
The data pipeline described in other post (link) gave an overview of the complete data flow from external api to visualization.
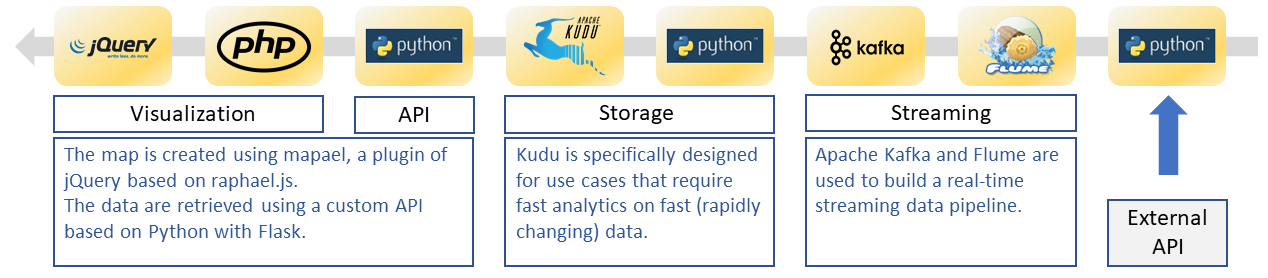
A Kafka consumer is created using the Python Client for Kafka and the python Kudu interfaces allows the data to be sent to a Kudu table.
The Kafka consumers is created using a consumer group id which allows offset management to be handled by Kafka.
from kafka import KafkaConsumer
import kudu
import json
import datetime
consumer = KafkaConsumer('aircheckr_city', bootstrap_servers='192.168.1.238:9092', group_id='test_kudu', auto_offset_reset='earliest')
while True:
msg=next(consumer)
To be fault-tolerant, committing offsets is mandatory.
…. consumer.commit_async()
Before starting the infinite loop, a connection to the Kudu master is established:
client = kudu.connect(host='ubuntu243', port=7051)
When a message is read from the kafka topic, the records is send to Kudu (after transformation – not shown):
table = client.table('impala::default.kudu_aircheckr_stream')
session = client.new_session()
op = table.new_insert(dictval)
session.apply(op)
try:
session.flush()
except kudu.KuduBadStatus as e:
print("kudu bad status during flush")
print(session.get_pending_errors())
Note the naming conventions for Kudu tables that are created via impala: impala::database_name.table_name.
Note that this is a solution for low volumes because the python script is executed on the node where the script is installed and not the complete cluster. If execution on the cluster is needed other solution such as spark streaming need to be considered.
Links
Python client for Apache Kafka: https://github.com/dpkp/kafka-python
Python interface for Apache Kudu: https://github.com/cloudera/kudu/tree/master/python
Using Kafka Consumer Groups: https://docs.confluent.io/current/clients/consumer.html
Kudu tables naming conventions: https://www.cloudera.com/documentation/enterprise/5-11-x/topics/impala_tables.html#kudu_tables