
It are challenging times; not only is there higher volumes on data to handle, and most predictions expect are an exponential increase, but more requests are received to have real-time or near real-time data. The value of real-time business data decreases when it gets older, but at the same time there is a higher demand on integrated and high-quality data which requires more processing power.
The main uses cases for real-time data marts are [2]:
- Operational reporting and dashboards: Operational data that needs to be visualized for immediate actions using business intelligence tools.
- Query offloading: replication of high-cost or legacy OLTP databases to another infrastructure of easy querying without impacts on the applications.
- Real-time analytics: the data and the results of any predictive analytics process require often that actions are taken with the shortest delay possible, for example fraud detection.
There are large differences between the requirements for a real-time data mart and those for an enterprise data warehouse [6]. The following table lists some of the requirements of each data store:
| Real-time (RT) data mart | Enterprise data warehouse (EDW) | |
| Description | Data is available in reports and dashboards from several source systems after a few seconds or a few minutes the latest. | Data is available in reports and dashboards from ALL source systems next day or later. There are integrated and of high quality. |
| Latency | Seconds/minutes | Days/months |
| Capture | Event-based/streaming | Batch |
| Processing requirements | Moderate | High |
| Target loading impact | Low impact | High |
| User access/queries | Yes | No (used to feed the user access layer with data marts) |
The techniques used vary mostly on the latency of data integration, from daily/monthly batches to streaming real-time integration. The capture of data from the application sources can be performed through queries that filter based on a timestamp or a flag, or through a change data capture (CDC) mechanism that detects any changes as it is happening. In case of streaming, the events are captured as they occur and are immediately integrated in the data mart. With a batch process, changes after a specified period are detected, rather than events. A daily batch mechanism is most suitable if intra-day freshness is not required for the data, such as longer-term trends or data that is only calculated once daily, for example financial close information. Batch loads might be performed in a downtime window, if the business model doesn’t require 24-hr availability of the data warehouse.
A well-known architecture to solve these conflicting requirements is the lambda architecture [3]. This architecture takes advantage of both batch- and stream-processing methods.
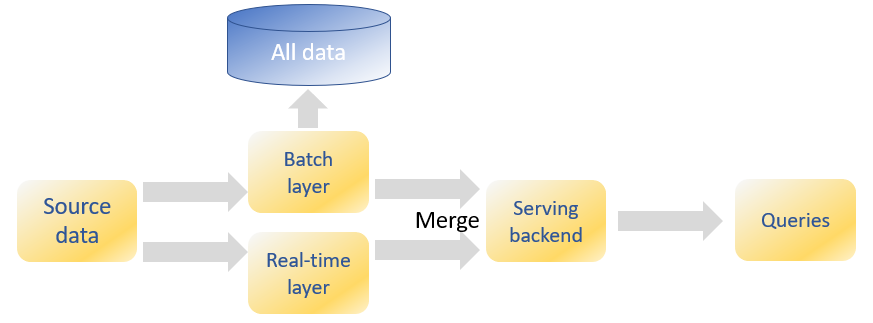
A more recent approach is the Kappa architecture [4], which removes the batch layer from the lambda architecture. It has many advantages, such as the need to write and maintain only code for the streaming layer. There are no two group of codes or frameworks; one for the batch and another for the streaming layer.
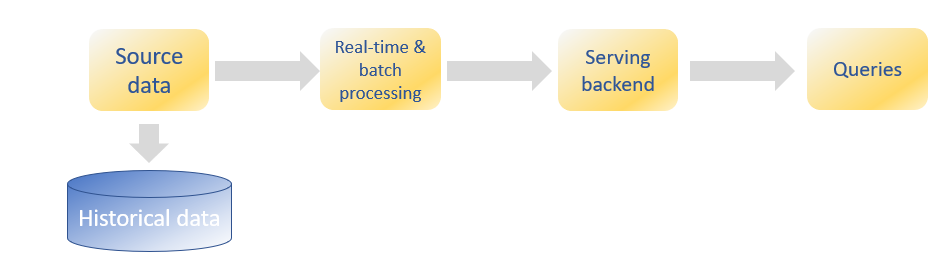
The kappa architecture treats a batch as a special case of a stream. A batch is a data set with a start and an end (bounded), while a stream has no start or end and is infinite (unbounded). Because a batch is a bounded stream, one can conclude that batch processing is a subset of stream processing. Hence, the Lambda batch layer results can also be obtained by using a streaming engine. This simplification reduces the architecture to a single streaming engine capable of ingesting the needed volumes of data to handle both batch and real-time processing. Overall system complexity significantly decreases with Kappa architecture.
The streams (real-time and batch) are send to the serving back-end after processing. This serving back-end can contain the several components of a BI stack such as a data warehouse or a real-time data mart.
The BI architecture for the Serving Layer is shown in the next figure.
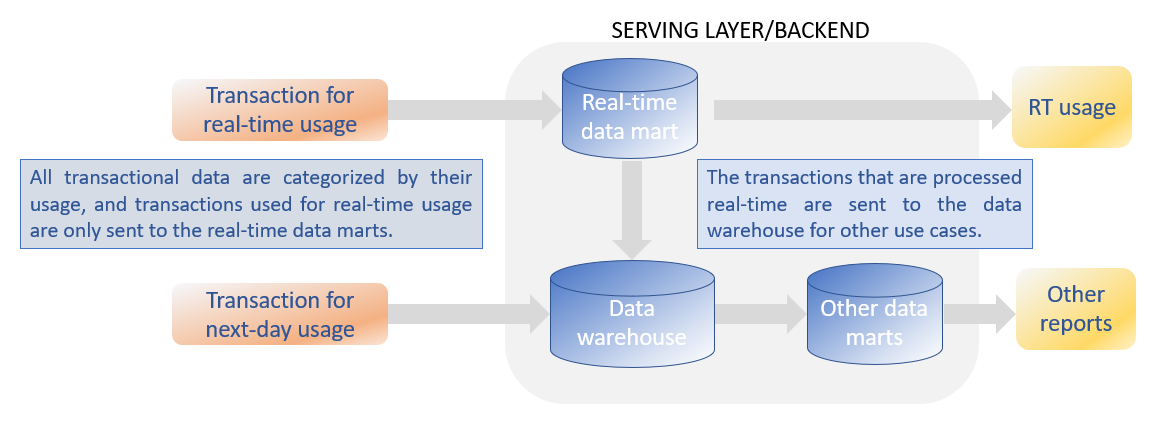
The transactions that are needed for real-time data marts are sent immediately to the data marts, while all other transactions (and referential data) are sent the data warehouse for long-term storage. The real-time transactions are sent in a second step to the data warehouse which makes that all data are present in the data warehouse. Note that this design pattern is also presented for the operational data store [1].
There will be many real-time data marts for a specific use case or business channel, but the data marts are should all use the same platform as the data warehouse and be integrated as described before. Else tactical/operational decision and strategic decision support will not be based on the same data which will lead to inconsistencies and poor execution. [5]
[1] Operational data store https://en.wikipedia.org/wiki/Operational_data_store
[2] Best Practices for Real-Time Data Warehousing http://www.oracle.com/us/products/middleware/data-integration/realtime-data-warehousing-bp-2167237.pdf
[3] Lambda Architecture http://lambda-architecture.net/
[4] Understand Kappa Architecture in 2 minutes http://dataottam.com/2016/06/02/understand-kappa-architecture-in-2-minutes/
[5] Ten Mistakes to Avoid When Constructing a Real-Time Data Warehouse http://www.bi-bestpractices.com/view-articles/4766
[6] What is operational data store vs. data warehouse technology? http://searchdatamanagement.techtarget.com/answer/What-is-an-operational-data-store-vs-a-data-warehouse