
The pollution data are retrieved from an external api (see this post for more information) and send to Apache Flume. Apache Flume is a service for streaming data into Hadoop and other streaming applications. Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data.
For the streaming data pipeline on pollution in Flanders, the data was send to Hadoop HDFS and to Apache Kafka. A Flume source captures the data received from the external api.
The python code to send the data to the flume agent using json format. The standard JSONHandler needs a header and a body section. Also the headers of the request requires to specify the content type :
url_flume = 'http://<ip-address>:<port>'
payload = [{'headers': {}, 'body': data_clean }]
headers = {'content-type': 'application/json'}
response = requests.post(url_flume, data=json.dumps(payload),
headers=headers)
Every Flume agent has normally one source, a memory channel and a sink. The incoming data can however be sent to more than one sink. For each additional sink, the source needs another memory channel.
A flow multiplexer is defined that can replicate or selectively route an event to one or more channels.
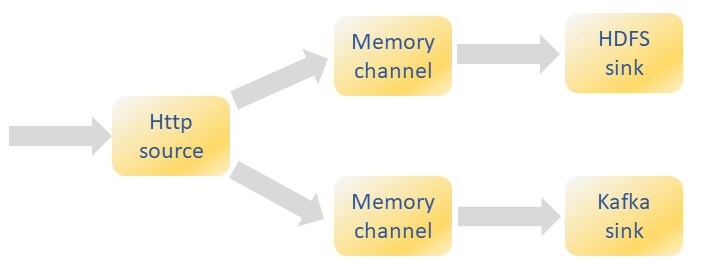
The configuration of the agent to receive and send the data is given below.
# Name the components on this agent aircheckr1.sources = http_aircheckr aircheckr1.sinks = hdfs_sink kafka_sink aircheckr1.channels = channel_hdfs channel_kafka # Describe/configure the source aircheckr1.sources.http_aircheckr.type = http aircheckr1.sources.http_aircheckr.bind = 0.0.0.0 aircheckr1.sources.http_aircheckr.port = 9260 # Describe the sink aircheckr1.sinks.hdfs_sink.type = hdfs aircheckr1.sinks.hdfs_sink.hdfs.path = hdfs://192.168.1.242/flume/aircheckr aircheckr1.sinks.hdfs_sink.hdfs.rollInterval = 86400 aircheckr1.sinks.hdfs_sink.hdfs.rollSize = 0 aircheckr1.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink aircheckr1.sinks.kakfa_sink.kafka.bootstrap.servers = ubuntu238:9092 aircheckr1.sinks.kafka_sink.kafka.topic = aircheckr aircheckr1.sinks.kafka_sink.flumeBatchSize = 10 # Use a channel which buffers events in memory aircheckr1.channels.channel_hdfs.type = memory aircheckr1.channels.channel_hdfs.capacity = 1000 aircheckr1.channels.channel_hdfs.transactionCapacity = 500 aircheckr1.channels.channel_kafka.type = memory aircheckr1.channels.channel_kafka.capacity = 1000 aircheckr1.channels.channel_kafka.transactionCapacity = 10 # Bind the source and sinks to the channel aircheckr1.sources.http_aircheckr.channels = channel_hdfs channel_kafka aircheckr1.sinks.hdfs_sink.channel = channel_hdfs aircheckr1.sinks.kafka_sink.channel = channel_kafka
Links:
Apache Flume: https://flume.apache.org/
2 Replies to “Sending data to Flume using Python”