It is common to divide data management environments in two classes, one being online transaction processing (OLTP), the other class is online analytical processing (OLAP). OLTP is characterized by large numbers of online transactions (create, replace, update, delete or CRUD operations). These transactions should happen very fast; applications running on top of a OLTP database often require instant responses. OLAP on the other hand is more concerned with historical data on which complex analytical processes need to run. The volumes of the transactions are much lower compared to OLTP, but the transactions are often very complex and involve larger amount of data. OLAP applications typically use machine learning techniques and the data are stored in a multi-dimensional schema or star schema.
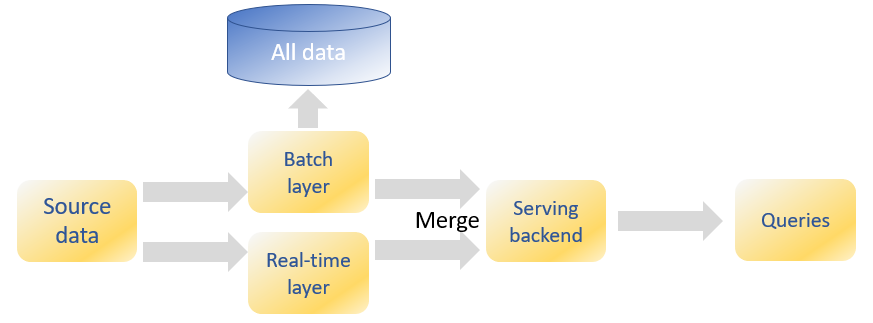
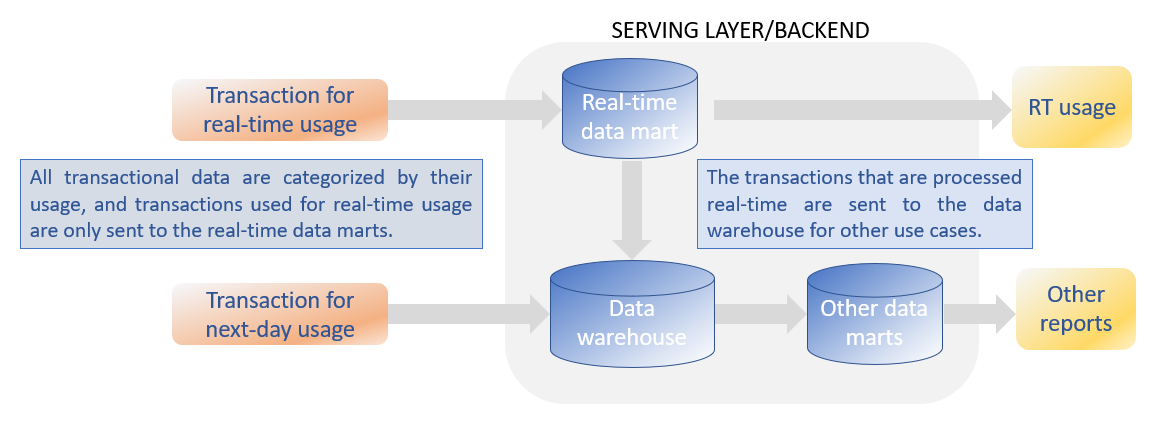
Because the same database instance is not able to support both activities with opposing demands, separate databases are setup, one database for OLTP, the other database supporting the analytical type of processes (OLAP). But the consequence of this segregation is that a constant dataflow needs to exist from the OLTP database to the OLAP database. This dataflow is called ETL (extract, transform and load). The ETL process will store the data from the OLTP database in another isolated environment such as a data warehouse or lately often in a data lake. Often a second ETL will move data from the data warehouse to another data store, called the data mart on which reports and ad-hoc queries are performed. Data warehouses rely on traditional RDBMS platforms, and the dimensional models in data marts are aligned to support the performance levels in accordance with the frequent and complex business analysis queries.
This process worked well until now because the reports were needed one day later. This time window was needed by the ETL process to move data from the source application to the data warehouses and the data marts. But lately there an increased demand for real-time reporting systems with the emergence of streaming data from sensors (IoT, internet of things), machine to machine data, social media and other operational data. On top of these new type of data, real-time analytics is required to provide recommendations to users and more personalized responses to any user interaction.
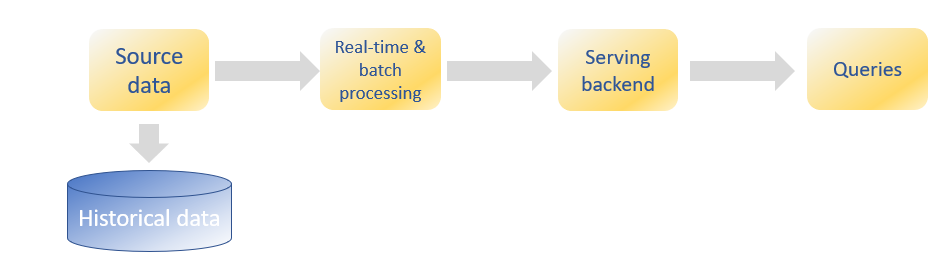
New database technologies have emerged the latest years that support hybrid workloads within one database instance. These new database systems take advantage of the new hardware technologies such as sold-state disks (SSD) and cost reductions in RAM memory. Gartner coined the term “Hybrid Transactional and Analytical Processing” (HTAP) to describe this new type of databases [3]. These database technologies allow for transactional and analytical processing to execute at the same time and on the same data [2]. Consequently, real-time processing and reports are possible at the same time that the transactions occur. Another term used to describe this type of processing is transactional analytics. The term indicates that insight and decision take place instantaneously with a transaction, e.g. at the moment of engagement with the customer, partner or device.
For example, a customer wants to buy a tablet in an online shop. During the selection process, the customer will get personalized recommendations in real time based on his previous and current surfing behavior. Once a tablet is put in the shopping basket and the payment transaction is initiated, fraud analytics is initiated in real time which is another transactional analytics process. In less than a minute all customer interactions are finalized with the aim to increase customer satisfaction and revenue. Note that these functions, fraud detection and recommendation systems exist today, but it requires a heterogenous and complex architecture. HTAP will simplify the architecture dramatically because all data are available in the same database and all analytical processes will occur in the same environment.
Traditional data architectures separate the transactions from the analytics which run on separate systems, each optimized for the particular type of processes and requirements. Data is copied from one system to the other one and those integration data pipelines will only add more complexity.
When we compare current architecture with a HTAP based architecture, the following differences are apparent:
- Complex architecture. Current data architectures are complex because data is moved from the transactional systems to the analytical systems using ETL and other integration tools to move and transform the data. Also, enterprise service buses (ESB) are used to manage this complex architecture. These tools are not required anymore if transactional and analytical processes occur in the same system.
- Real-time analytics. Because data is moved from the transactional to the analytical systems, a large time gap exists between the moment the transactions occurred and the moment these transactions can be analyzed.
- Data duplication. Copying data from one system to the other system not only duplicates the data, but every complex ETL process might introduce data quality problems which leads to inconsistencies in the reporting.
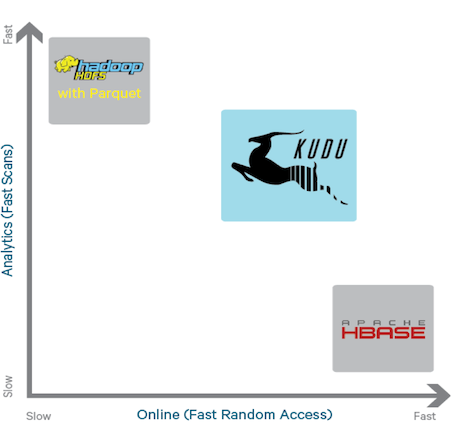
There are today several database implementations that use one or more HTAP features [1] such SAP HANA, MemSQL, IBM dashDB, Hyper, Apache Kudu, ArangoDB, Aerospike, etc.
[1] Hybrid Transactional/Analytical Processing: A Survey, Fatma Özcan et al. SIGMOD ’17, May 14–19, 2017, Chicago, IL, USA.
[2] Hybrid transactional/analytical processing (HTAP) https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing_(HTAP)
[3] Hybrid Transaction/Analytical Processing Will Foster Opportunities for Dramatic Business Innovation. Pezzini, Massimo et al. Gartner. 28 January 2014