
Apache Superset is a visualization tool, originally developed by Airbnb [1]. The goal to develop this tool is to empower every user of data, especially users for which SQL is often a too high barrier. A second goal is to allow users to explore and discover insights with a user-friendly interface. The solution to both of these challenges is the development of Superset. Only recently it became an Apache project [2].
Once Apache superset is running, a new database connection is made using Impala. The URI has the format impala://<host>:21050/<database>.
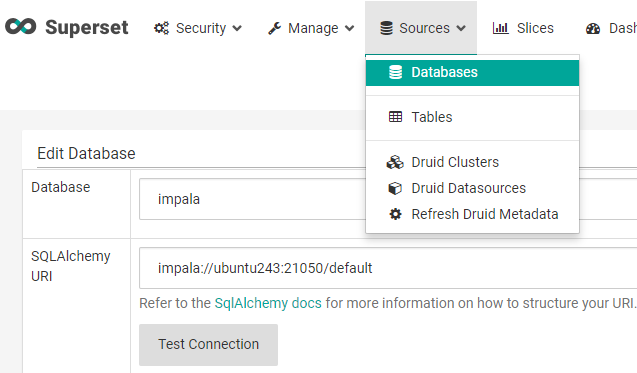
Note that first the impala driver needs to be installed (pip install impyla) [3]
Next, a table is created to enable the usage of a dataset inside a slice or dashboard. Because only one data source can be used for each slice, the tables will often be a view of several tables that are joined beforehand. [4] This means if your tables are designed as dimensions and facts, a join between all tables needs to be made when the “table” is defined, or else a single table needs to be materialized that contain all table in the data source.
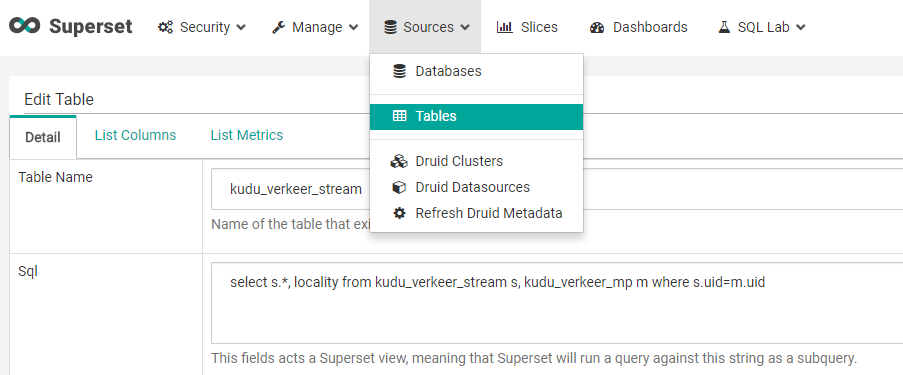
Once that table/view is defined, columns and metrics need to be defined before it can be used to define a slice.
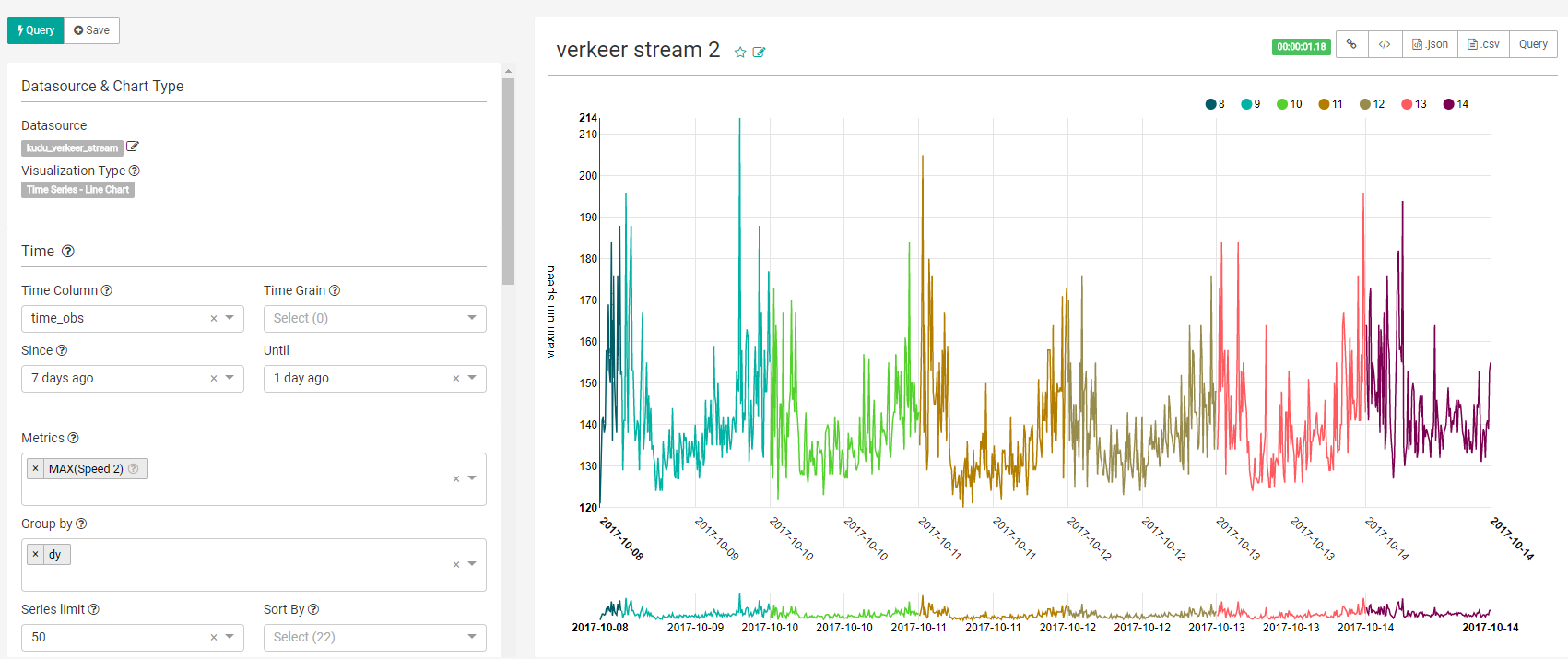
At last, the slice can be created and added to a dashboard.
Links
[1] Superset: Scaling Data Access and Visual Insights at Airbnb https://medium.com/airbnb-engineering/superset-scaling-data-access-and-visual-insights-at-airbnb-3ce3e9b88a7f
[2] Apache Superset (incubating) https://superset.incubator.apache.org/
[3] Installation & Configuration http://superset.apache.org/installation.html
[4] FAQ http://superset.apache.org/faq.html